
Last year we revised the workflow to insert special characters. Based on a design proposal the dialog was reimplemented in a Google Summer of Code project by Akshay Deep. The new dialog allows to easily browse through the list and to search for glyphs contained in the selected font. It also introduced Favorites (a user collection of glyphs that are used frequently) and a list of Recently Used glyphs. But some pieces got more or less intentionally lost and some parts of the redesign might have room for improvements. So here is an idea for the final touch.
Localization
The first issue is about localization. While we tried to make the default list of Favorites as usable as possible for everyone it has a bit of western focus with €¥£©ΣΩ≤≥∞π†‡. That brings us to the first two new requirements:
- Eve wants to use the Special Characters dialog with a regional configuration.
tdf#120899: Make the predefined list of favorite special characters localizable - Eve wants to increase the number of favorites and recently used as she has to deal frequently with up to 48 different special characters.
tdf#120753: Provide an option to extend the number of Favorites and Recents for Special Characters
(Eve and Benjamin are our prototypical users, called Persona)
There is no objection to have Favorites defined by the localization teams, which means you get a default set depending on the installed language. But we controversially discussed the second part to have more items. Problem here is that many items clutter the UI, and 16 is enough for most users. So if that is going to be implemented it has to be an option.
Listing
The Unicode standard groups glyphs in blocks (or subsets). We provide access to these subsets via the dropdown but don’t show where it starts and end.
- Benjamin wants to easily notice new sections in the unicode list to understand the structure.
- Benjamin wants to get favorites and recently used characters highlighted to improve the understanding.
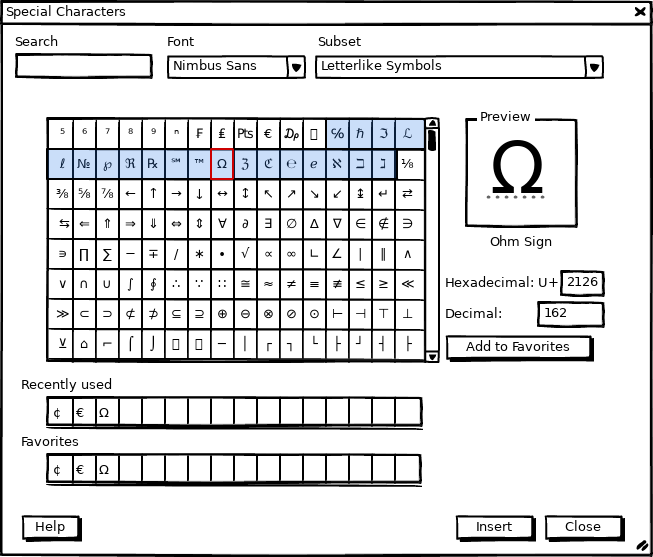
The proposal is to highlight the subset (the light blue in figure 1) and independently also the Favorites (red frame).
The reason to understand the list is that a font not necessarily contains all glyphs. And if you know the code point within the unicode list it’s hard to detect it. The continuous list doesn’t allow to label columns and rows as known from specialized tool such as BabelMap.
- Benjamin wants rows/cols labeled to learn the unicode numbers.
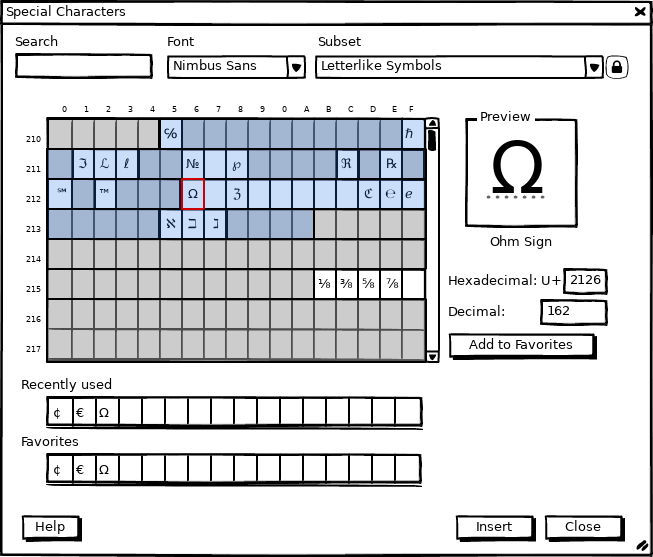
Figure 2 shows a solution where a small icon (e.g. a lock on/off) toggles the view. After switching on, the column and row headers are shown and allow to read code points over the whole table. And since empty code points needs to be shown too, but as disabled entries, the coverage of the selected font becomes clear.
Searching
Another requests is to search for a glyph by the code point. For example, you know U+1D538 but don’t remember the glyph’s name (mathematical double-struck capital A) or just write it wrongly without the dash, and want to search for the font that contains this glyph, which is not possible yet.
- Eve wants to search by code points to find the font that contains this glyph.
tdf#111816: Cannot find special character if does not know character name but number
The idea is to adopt the lock icon from above and keep the hexadecimal value constant when changing the font name (it’s shown in Figure 3 below). For convenience the “lock” could be opened automatically when the search term changes.
Buffering
In the previous dialog we had a small text field where double-clicked glyphs ended up, and the full string was inserted into the document on insert. This buffer is not only a kind of convenience feature it also allows to combine more than one glyph into the actual character.
- Eve wants to assemble a couple of glyphs into a string that finally is inserted into the document.
tdf#115477: Restore edit buffer to extend the Special Character dialog

The solution spoils the clean dialog a bit but provides more flexibility: A radio button allows to send the double-clicked glyphs directly into the document (the current status) or into a buffer, and this content goes finally into the document per Insert.
Fancy stuff
Last but not least we had two ideas that were not implemented but sound like cool enhancements.
- Benjamin wants to see the font baseline in the preview to understand the layout.
- Eve wants to find a certain character by just drawing it since she not always knows the unicode name to search for.
tdf#114721: Special char: find the char by drawing it
The baseline is shown in all documents but if character recognition becomes real (an example how it works can be found at http://shapecatcher.com/ and some ideas to implement it are in the ticket) we need access to it in the UI. Perhaps per switch on the preview? Tell us your ideas.
And please join the discussion if any of those changes make sense to you. We need expertise from people who stress the special character dialog and benefit from those envisioned modifications.
One thought on “Special Characters: The Final Touch”
Comments are closed.